
メモリとは、AIが継続的な前提や好みを「覚えておく」仕組みです。RAGの「都度参照」とは役割が違います。
この記事でわかること
- RAGの「参照」とメモリの「継続」の違い
- メモリが強い場面と、万能ではない理由
- 実務ではRAGとメモリを両方使う場面が多い理由
生成AIの話をしていると、少し似た雰囲気の言葉がいくつか出てきます。RAG、検索、メモリ。どれも「AIが何かを持っている感じ」がする。だから最初は混同しやすいです。
特に多いのが、「RAGって、AIが覚えることではないの?」「メモリってRAGと何が違うの?」「どっちも前提を持たせる仕組みでは?」という疑問です。すごく自然な疑問ですが、実際にはRAGとメモリは違います。
最初にひとことで言うと、RAGは必要な情報を「取りに行く」仕組み。メモリは継続的な前提を「覚えておく」仕組みです。この違いが分かると、生成AIとの付き合い方が整理しやすくなります。
RAGは「参照」、メモリは「継続」
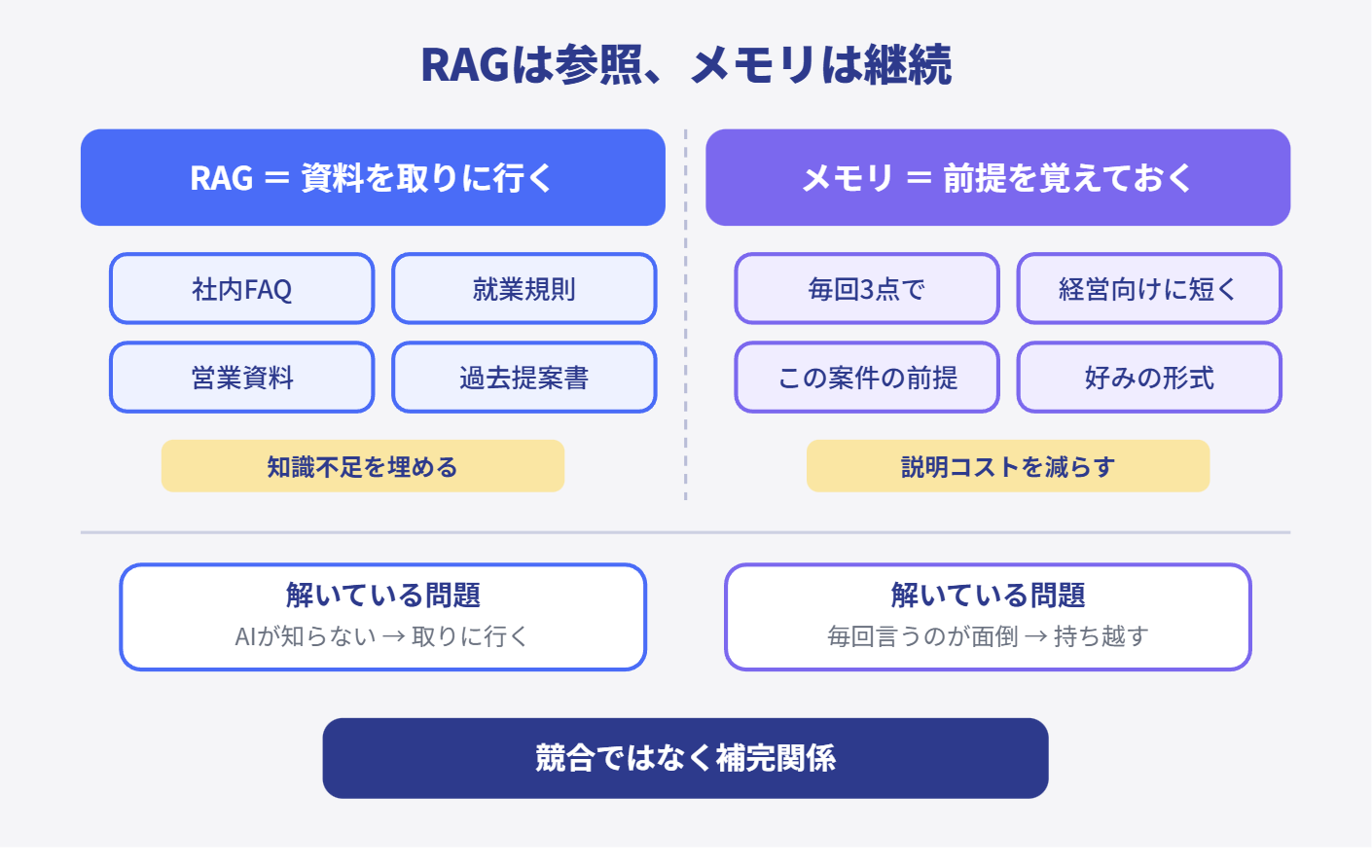
前回までで見てきたように、RAGは必要な資料や知識をその場で探して参照する仕組みでした。FAQを見る、規程を見る、営業資料を見る、過去提案書を見る。外部にある情報源を答えの前に足すことが強みです。
一方でメモリは少し役割が違います。メモリが扱うのは、もっと会話や利用者に紐づく継続的な前提です。
たとえば、この人は経営向けの短い説明を好む、毎回表形式で出した方が使いやすい、このプロジェクトではこの言葉づかいを優先したい、このチャットではこの前提で考えている。こういうものです。
つまりRAGは「資料を見に行く」。メモリは「前提を持ち越す」。
メモリは百科事典のようなものというより、会話や利用の流れを継続しやすくするものと見た方が近いです。人間でも、同じ相手と何度も仕事をしていると、「この人は結論から話した方がいい」「この案件ではこの表現を使わない」みたいなことを覚えます。その結果、毎回ゼロから説明しなくてよくなる。メモリも、それに近い役割を持ちます。
つまりメモリは、AIを「物知り」にするというより、「継続的に付き合いやすくする」ための仕組みです。
RAGが向いているもの、メモリが向いているもの
ここを分けて考えると分かりやすいです。
RAGが向いているのは、社内規程、FAQ、製品資料、マニュアル、過去提案書、ドキュメント群。外に存在する資料を見に行く話です。つまり知識の参照。
メモリが向いているのは、好みの出力形式、毎回の前提条件、継続しているプロジェクト文脈、よく使う観点、利用者ごとの傾向。毎回同じ説明を繰り返さなくてよくする話です。つまり前提の持続。
たとえば「就業規則に照らして答えて」はRAGの話です。「毎回、経営向けに短く3点でまとめて」はメモリの話です。同じ「AIに前提を持たせる」ように見えても、中身は違います。
もう少し実務的に言えば、RAGが解いている問題は知識不足、メモリが解いている問題は説明コストです。AIが社内情報を知らないからRAGで取りに行く。毎回同じ好みや形式を伝えるのが重いからメモリで持ち越す。
メモリがないと、生成AIを毎回使うたびに、自分の立場、相手の想定、欲しい形式、プロジェクトの前提を全部書く必要があります。メモリがあればその負担が減る。生成AIを「毎回初対面の相手」から少しだけ卒業させる仕組みとも言えます。
メモリは便利だが、万能ではない
メモリという言葉を聞くと、「じゃあ全部覚えておいてもらえばいいのでは?」と思いたくなります。
でもそこは少し慎重に見た方がいいです。メモリが扱うのは継続的な前提です。便利な反面、古い前提が残る、今回だけの例外に弱い、状況が変わったのに以前の文脈を引きずる、どこまでを覚えておくべきかが難しい、ということも起こりえます。
人間でも、前に聞いた前提を引きずりすぎるとズレます。メモリも少し似ています。だからメモリは強い。でも「一度覚えたら全部うまくいく」ものではありません。
もうひとつ大事なのは、メモリは会話履歴と完全に同じではないことです。会話履歴はその場で交わされた内容そのもの。一方メモリは、その中から継続的に持っておくと役立つ前提を残す感覚に近い。
そして、メモリは「最新の事実」を保証する仕組みでもありません。法改正の最新情報、更新された価格表、新版の社内規程のようなものは、メモリで持つには向きません。それらは変わるからです。継続前提として残すより、必要なときに参照し直した方がいい。
つまり、変わりにくい前提はメモリ向き、変わりうる情報はRAGや検索向き。この分け方は実務的です。
仕事では、RAGとメモリを両方使いたい場面が多い
ここまで分けてきましたが、実務では両方必要なことが多いです。
たとえば、社内FAQを参照しながら、毎回役員向けに短くまとめてほしい。この場合、社内FAQはRAG、役員向けに短くはメモリです。
あるいは、過去提案書を踏まえながら、この案件では競合比較を先に出したい。この場合も、過去提案書はRAG、この案件での進め方はメモリです。
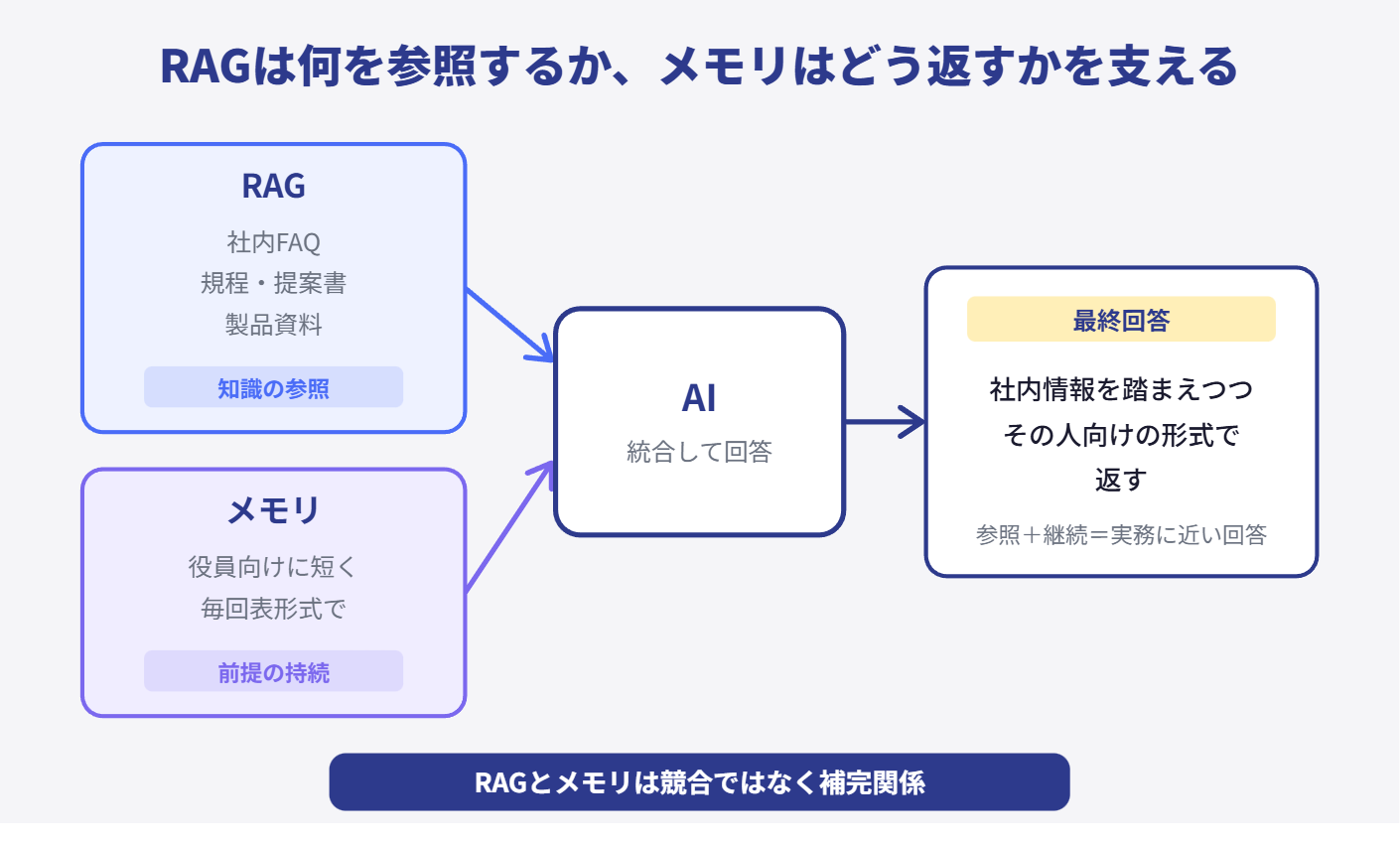
つまり実務では、RAGが「何を参照するか」を支え、メモリが「どう返すかの継続」を支えることが多い。この2つは競合ではなく、補完関係です。
RAGが寄せるのは主にその会社の情報。メモリが寄せるのはその人やその会話の文脈です。いつも簡潔な要約を好む人、いつも比較表で見たい人、いつも結論から見たい人。こういう傾向が分かると、AIはだんだんその人向けに寄っていく。
なので、RAGが「会社の文脈」を持ち込むものだとすれば、メモリは「利用者や会話の文脈」を持ち込むものだと考えると整理しやすいです。
RAGとメモリの違いが分かると、AIに何を持たせるべきかが見えてくる
ここまでの話をシンプルにまとめます。
RAGとメモリの違いを比較する
| RAG | メモリ | |
|---|---|---|
| 役割 | 必要な情報をその場で取りに行く | 継続的な前提を覚えておく |
| 扱うもの | 社内資料・FAQ・規程などの知識 | 好みの出力形式・プロジェクト前提・話し方の傾向 |
| 解決する問題 | 知識不足 | 説明コスト(毎回同じ前提を伝える負担) |
| 情報の性質 | 変わりうる(最新版がある) | 変わりにくい(好み・方針・スタイル) |
| 関係性 | 補完関係 | 補完関係 |
よくある疑問
メモリがあれば、RAGは不要ですか?
不要ではありません。メモリが解決するのは「毎回同じ前提を伝える負担」であり、「社内情報を知らない」問題は解決しません。両方併用が理想です。
メモリは会話履歴と同じですか?
同じではありません。会話履歴はその場で交わされた内容そのものです。メモリはその中から「継続的に持っておくと役立つ前提」を残す感覚に近いです。
メモリに向かない情報はありますか?
変わりやすい情報(法改正・価格表・新版規程等)はメモリには向きません。必要なときにRAGや検索で参照し直す方が安全です。
まとめ
この記事のポイントを3つにまとめます。
- RAGは「知識を参照する」仕組み、メモリは「前提を継続する」仕組み。解決する問題が違う
- メモリはAIを「毎回初対面」から卒業させる仕組みだが、古い前提を引きずるリスクもある
- 実務ではRAG(何を参照するか)とメモリ(どう返すかの継続)を両方使うのが理想
次回は「ファインチューニングとは何か」をやります。
ここまでで、Web検索は外を見る、RAGは内の資料を参照する、メモリは継続前提を覚えるという3つの違いが見えてきました。すると次に自然に出てくるのがファインチューニングです。「資料を参照するのではなく、モデル側を調整するって何なの?」次はそこをやります。


