
ファインチューニングとは、モデルそのものの出力傾向を事前に寄せておく仕組みです。RAGの「参照」やメモリの「継続」とは属する層が違います。
この記事でわかること
- 生成AIの文脈には「即時・外部参照・永続」の3層があること
- ファインチューニングは「知識を足す」より「型を染み込ませる」に近い理由
- RAG・メモリ・ファインチューニングの使い分け方
生成AIの仕組みを少し学び始めると、どこかでこう感じます。RAGもある、Web検索もある、メモリもある、さらにファインチューニングもある。言葉は増えていく。でも頭の中では少し混ざる。
どれも「AIに何かを持たせる仕組み」に見えるからです。
でも実際には、「AIに何を、どのタイミングで持たせるのか」で分けて考えると整理しやすくなります。
最初に結論を書くと、生成AIに渡る文脈や前提は、大きく3種類に分けられます。その場で入れるもの、必要なときに取りに行くもの、事前に覚えさせたり残したりしておくもの。この3つです。
この地図が見えると、RAGとメモリとファインチューニングの違いが分かりやすくなります。
コンテキストには3種類ある
生成AIに何かをやらせるとき、AIは何もない空中で答えているわけではありません。何らかの前提や文脈をもとに動いています。ただしその文脈の入り方には種類があります。
| 層 | 概要 | 主な手法 | 主な用途 |
|---|---|---|---|
| 即時コンテキスト | その場で入力する情報 | テキスト入力、ファイル添付、プロンプト | 単発業務、文書要約、個別相談 |
| 外部参照コンテキスト | 必要に応じて外から取得する情報 | RAG、Web検索 | FAQ、社内文書参照、情報検索 |
| 永続コンテキスト | 事前に学習・保存しておく情報や傾向 | ファインチューニング、メモリ | 自社専用AI、定型応答、出力傾向の安定化 |
つまり、その場で渡すものもあれば、必要になってから取りに行くものもあれば、あらかじめ持たせておくものもある。ファインチューニングはこの中で永続コンテキストに入ります。
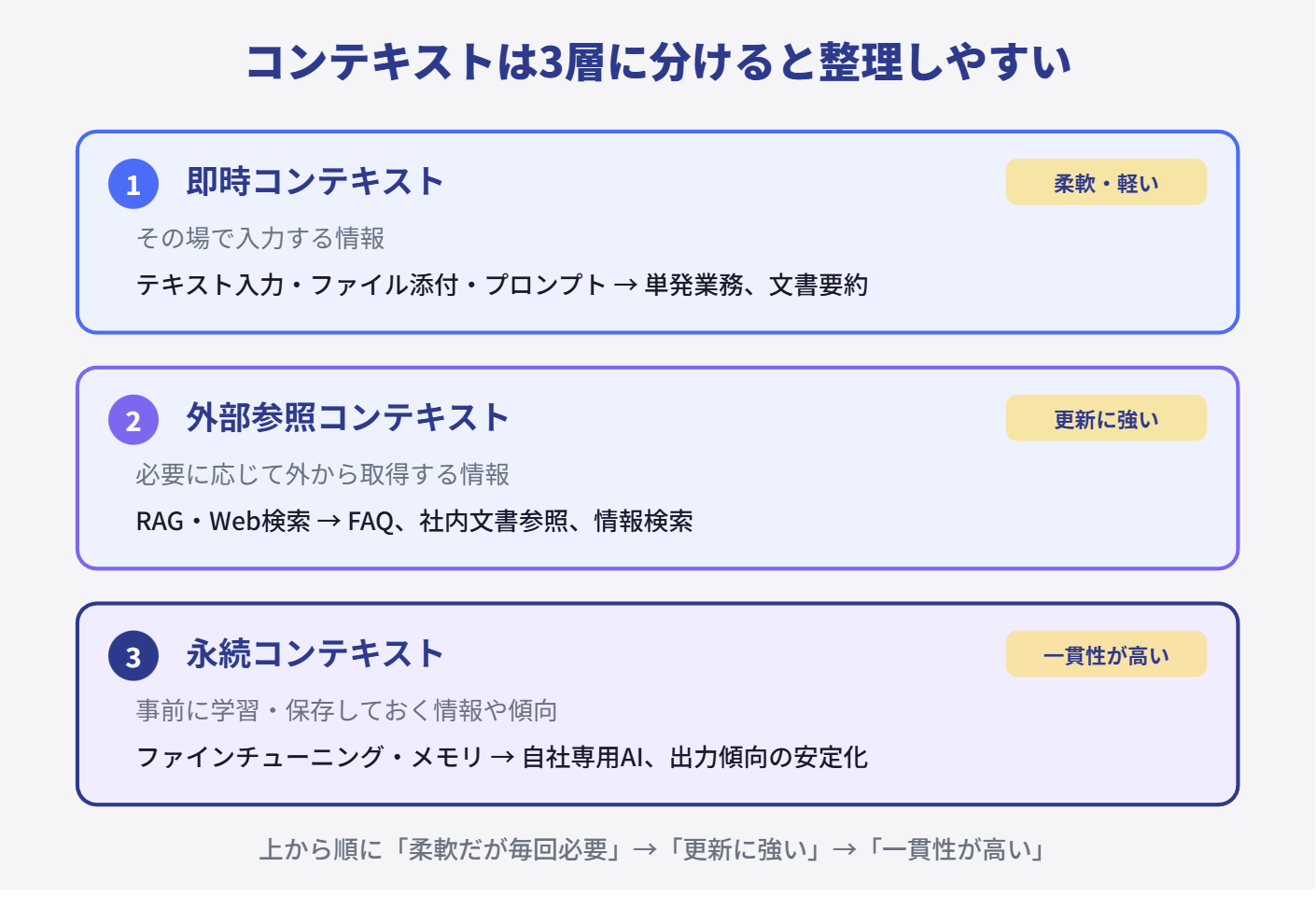
即時コンテキストと外部参照コンテキスト
一番分かりやすいのが、その場で渡す情報です。今回の依頼内容、その場で貼った文章、添付したPDF、URLで渡したページ、今回だけの条件、欲しい出力形式。こういうものです。
柔軟で毎回必要なものをその場で渡せる。だから単発の作業や一回きりの依頼には強い。一方で、毎回入れないといけないという特徴もあります。プロンプトも基本的にはここです。つまりプロンプトは、その場の条件をAIに渡す方法のひとつです。
次が、必要なときに外から取りに行く情報。ここに入るのがこれまで見てきたRAGとWeb検索です。社内FAQを見て答える、就業規則を参照する、最新ニュースを探す、製品資料を見ながら答える。
この層の強みは更新に強いことです。資料が更新されても、検索先や参照先を更新していれば追いつきやすい。外の最新情報はWeb検索、内側の資料やFAQはRAG。「取りに行く層」として見ると整理しやすいです。
永続コンテキスト:メモリとファインチューニングの違い
3つ目が、事前に持たせておく情報や傾向です。ここに入るのがファインチューニングとメモリです。
ただし、この2つも同じではありません。大きく見ると「毎回ゼロから渡さなくても、ある程度継続して残る前提」という点では同じ層に置けます。でも中身は違います。
メモリは、利用者や会話の前提を覚えておくもの。毎回同じ説明をしなくてよくする。好みや継続条件を持ち越しやすくする。
ファインチューニングは、モデルそのものの出力傾向を寄せるもの。特定の形式や文体を安定させる。ある種のタスクに強い振る舞いを持たせる。
つまり、メモリは「会話や利用の継続」に近い。ファインチューニングは「モデル自体のクセづけ」に近い。この差は大きいです。
ファインチューニングは「知識を足す」より「振る舞いを寄せる」もの
ファインチューニングという言葉を聞くと、どうしても「社内知識を覚えさせる」ように見えやすい。でも今回の3層で見ると分かりやすいです。
ファインチューニングは、外から資料を取りに行く層ではありません。RAGのように知識を都度参照するものではない。そうではなく、AIの返し方や反応の傾向を、あらかじめ寄せておく層です。
たとえば、この文体で返しやすくする、この形式で整理しやすくする、この分類基準でラベルづけしやすくする、この種類の応答に安定して寄せる。こういうものです。
つまりファインチューニングは知識を取りに行く仕組みではなく、出力の型や傾向を持たせる仕組みとして理解した方がズレにくいです。
この見方があると、RAGとファインチューニングの関係も分かりやすくなります。そもそも属している層が違う。RAGは外部参照コンテキスト、ファインチューニングは永続コンテキスト。RAGは「必要な知識を取りに行く」、ファインチューニングは「返し方を寄せておく」です。
だから「どちらが上か」ではなく、「今回はどの層の問題を解きたいのか」と考えられるようになります。FAQの内容はRAGで参照する。FAQらしい答え方やラベルの付け方はファインチューニングで安定させる。こういう組み合わせは自然です。

ファインチューニングは「覚えさせる」より「型を染み込ませる」
ここまでをシンプルにまとめます。
実務的な切り分けとしては、次の表のように整理できます。
| 変わる情報(更新が多い) | 固定したい傾向(安定させたい) | |
|---|---|---|
| 具体例 | 価格表・FAQ・規程・ニュース | 文体・分類基準・出力形式 |
| 向いている層 | 外部参照(RAG・Web検索) | 永続(ファインチューニング・メモリ) |
| 変わるもの | 参照先の情報が更新される | モデルの出力傾向が寄る |
| 残るもの | モデル自体はそのまま | 参照しない情報はそのまま |
この切り分けができるだけで迷いにくくなります。多くの混乱は「変わる情報」と「固定したい傾向」を同じ方法で解こうとすることから起きるからです。
よくある疑問
ファインチューニングで社内知識を覚えさせることはできますか?
理論上は可能ですが、知識の参照にはRAGの方が向いています。ファインチューニングは「返し方の型」を寄せるのが得意で、「最新の事実を知っているか」とは別の話です。
RAGとファインチューニングを両方使うことはありますか?
あります。FAQの内容はRAGで参照し、FAQらしい答え方やラベル付けはファインチューニングで安定させる、という組み合わせは自然です。
「変わる情報」と「固定したい傾向」の切り分けが分かりません。
最新価格表や規程改定のように更新されるものはRAGやWeb検索向きです。文体・分類基準・出力形式のように安定させたいものはファインチューニングやメモリ向きです。
まとめ
この記事のポイントを3つにまとめます。
- 生成AIの文脈には「即時・外部参照・永続」の3層があり、ファインチューニングは永続層に属する
- ファインチューニングは「知識を足す」より「出力の型や傾向を染み込ませる」仕組み
- 「変わる情報」はRAG・Web検索、「固定したい傾向」はファインチューニング・メモリという切り分けが実務で使える
次回は「ベクトル検索とは何か」をやります。
ここまでで即時コンテキスト、外部参照コンテキスト、永続コンテキストの3層が見えました。そのうえでRAGの裏側にもうひとつ大事な言葉があります。ベクトル検索です。なぜキーワードが完全一致していなくても「意味が近い」文書を拾えるのか。次はそこをやります。


