
トークンとは、AIが文章を読み書きするときの「細かい区切り」のことです。
この記事でわかること
- トークンが文字数でも単語数でもない理由
- コンテキスト長とトークンの関係
- トークンの感覚がプロンプト設計にどう活きるか
トークンとは何か。AIは文章をどう見ているのか
生成AIの話をしていると、どこかで必ず出てくる言葉があります。トークンです。 長文だとトークンをたくさん使う。このモデルはコンテキスト長が長い。入力上限は何万トークン。料金もトークン単位。こういう言い方を、どこかで見たことがある人も多いと思います。 でも、ここでけっこう多いのが、「なんとなく大事そうだけど、正直ちゃんとは分かっていない」という状態です。 文字数のことなのか。単語数のことなのか。雰囲気では分かるけれど、説明しようとすると少し曖昧になる。 この曖昧さをそのままにしておくと、あとで出てくる話が分かりにくくなります。なぜ長い資料を一度に入れられないことがあるのか、なぜ会話が長くなると前の文脈を落としやすくなるのか、なぜプロンプトを短く整理することに意味があるのか。 今回は、トークンとは何かをできるだけやさしく整理します。 最初にひとことで言うと、トークンは**AIが文章を読むときの「細かい区切り」**です。文字そのものでもなく、単語そのものでもない。だいたいその中間のような単位。まずはこの感覚が大事です。
AIは、人間と同じようには文章を見ていない
人間が文章を読むとき、文字を見て、単語を認識して、文の意味をつかんで、前後の流れを理解します。自然にやっているので、あまり意識しません。 一方で、AIは文章をそのまま人間のように見ているわけではありません。内部では、文章をいったん細かい単位に分けて扱います。 文字ごとでも、単語ごとでも、文ごとでもない。AIが扱いやすい粒度に分割された単位で見ている。それがトークンです。 つまりトークンとは、人間のための区切りではなく、AIが読み書きするための区切りです。
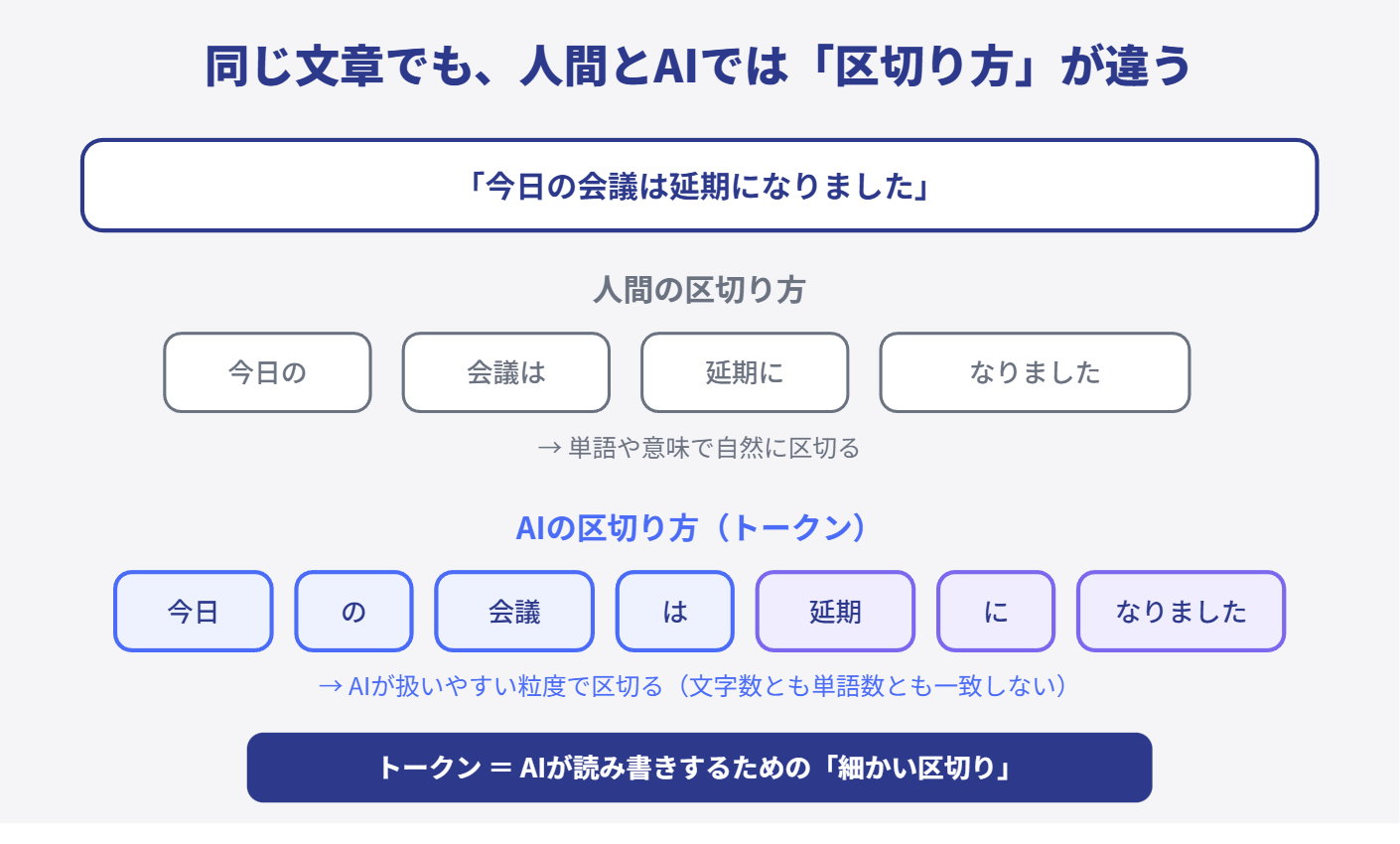
トークンは「文字数」でも「単語数」でもない
ここが最初に混乱しやすいところです。 トークンという言葉を聞くと、つい「単語のことかな」と思いやすい。英語だと特にそう見えます。 でも、実際にはそこまで単純ではありません。ある単語が1トークンになることもあれば、複数トークンに分かれることもある。逆に、短い記号や助詞が1トークンとして扱われることもある。 つまり、トークン=ちょうどいい単位に機械側で分けたものと考えた方が近いです。人間にとって自然な区切りと、AIにとって扱いやすい区切りは、少しずれることがある。だから「文字数」や「単語数」と1対1対応ではありません。 第1回で、生成AIは「次にもっともらしいものを少しずつ出していく」と書きました。この「少しずつ」の単位が、ざっくり言うとトークンです。つまりAIは、文章全体をいきなり扱うのではなく、トークン列として見て、次のトークンを予測しています。
コンテキスト長とは「AIの机の広さ」に近い
ここでよく一緒に出てくる言葉が、コンテキスト長です。 コンテキスト長とはざっくり言うと、AIが一度に見ながら考えられる情報量の上限です。ただしその「量」は文字数ではなく、トークンで数えられます。 机の上に資料を広げるイメージで考えると分かりやすいです。机が小さいと、広げられる資料は少ない。新しい資料を置くには何かをどける必要がある。逆に机が広いと、多くの資料を見ながら作業できる。 生成AIにとっての机の広さが、コンテキスト長です。机の上に置かれる紙の細かい単位が、トークンです。
だから、長い会話履歴、長い資料本文、追加の指示、出力で使うスペースは、みんな同じ机の上を取り合います。「なぜ長い会話だと前の文脈が落ちることがあるのか」も、この見方で理解しやすくなります。

トークンが分かると、プロンプトの考え方も変わる
ここは実務的に大事です。
プロンプトを書くとき、つい「長く丁寧に書けばいい」と思いやすい。もちろん、前提をきちんと渡すのは大事です。
でもトークンの考え方を知ると、長ければいいわけではないことも見えてきます。長い指示はその分だけ机の上を使うからです。
大事なのは、何をしてほしいか、何を前提にするか、何を制約にするか、どんな形で返してほしいかを、なるべく無駄なく渡すこと。
つまりトークンの感覚があると、プロンプトは「長い呪文」ではなく、限られた机の上に必要な情報をどう並べるかなんだな、と見えてきます。
AIは文章を「扱いやすい単位」に分けて見ている
ここまでの話をシンプルにまとめます。
トークンとは、AIが文章を読むときの内部的な区切り。文字数そのものでも単語数そのものでもなく、AIが扱いやすいように分けられた小さな単位。
そしてAIは、そのトークン列を見ながら次のトークンを予測していく。だから文章生成も、長文処理も、会話の保持も、料金も、この単位で動いています。
この感覚があると、生成AIが急に少し見えるようになります。人間のように文章を意味で丸ごと理解しているというより、文脈を踏まえながら小さな単位をつないで出力を作っている。まずはここを押さえれば十分です。
トークンと混同しやすい概念の違い
| トークン | 文字数 | 単語数 | |
|---|---|---|---|
| 何の単位か | AIが内部で使う処理単位 | 人間が見る文字の数 | 人間が認識する言葉の数 |
| 1対1対応か | しない(1単語が複数トークンになることがある) | 常に1文字=1 | スペース区切りで数える(英語の場合) |
| 料金計算に使うか | はい(APIの課金単位) | いいえ | いいえ |
| コンテキスト長の基準 | はい | いいえ | いいえ |
よくある疑問
日本語は英語よりトークン数が多くなるのですか?
一般的にはそうです。日本語は1文字が複数トークンに分かれやすいため、同じ内容でも英語より多くのトークンを消費します。
コンテキスト長が長ければ、何でも一度に処理できますか?
机の上に置ける量は増えますが、量が増えるほど処理速度やコストに影響が出ます。「全部入れればいい」ではなく、必要な情報を整理して渡す方が効果的です。
トークンの消費量を減らす方法はありますか?
指示を簡潔にする、重複を省く、必要な部分だけを抜粋して渡すなどが有効です。「丁寧に書く」ことと「長く書く」ことは別です。
まとめ
この記事のポイントを3つにまとめます。
- トークンとは、AIが文章を読み書きするための内部的な区切りで、文字数や単語数とは一致しない
- コンテキスト長は「AIの机の広さ」であり、入力・会話履歴・出力がすべて同じ机の上を取り合う
- トークンの感覚があると、プロンプトは「限られた机の上に必要な情報をどう並べるか」という設計になる
次回は「トランスフォーマーとは何か」をやります。
ここまでで、生成AIは続きを予測していること、その予測の単位がトークンであること、文章の長さや文脈の保持にもトークンの考え方が関わることが見えてきたと思います。では次に、そのトークン列を見ながらどこを重視して次を決めているのか。次はそこをやります。


